How to deal with Unbalanced Classes in Machine Learning (Precision, Recall, Oversampling and Undersampling)

Para ler em Português clique aqui (to read in Portuguese click here)
Note: English is not my native language, so I ask you to review any grammatical errors
Unbalanced classes (or as I like to say, 0’s more than 1’s, or vice versa) are everyday problems for any data scientist, I would say even the most common, although they are simple to get around, they are extremely important, for I decided to write this article today in order to clarify everything about this concept!
What you will read in this article:
- What are unbalanced classes ?;
- Precision and Recall;
- Identifying problems;
- Oversampling;
- Undersampling;
note: In this article I stopped to not use many lines of code, but know that they are available, by clicking here you will be redirected to the Google Colab Notebook in which the results of this article were removed, in case you want to directly apply the algorithms taught here, access it.
What are unbalanced classes?

To understand this concept we go to an example:
Imagine that you own a bank, and like all banks you have to deal with fraud, that is, buying feats that are not recognized by the real owner of the card. We don’t need much to understand that fraud happens, but obviously not at all times. The fact is that the chance of fraud occurring when purchasing a card is small when compared to the whole.
Thinking about it, you decide to create a Machine Learning Model that can predict these frauds. Knowing this difference between fraud, you get a data set that has approximately 1,000 fraud data and 1,000,000 non-fraud data. Realize that by creating a model and training it you are using less fraud data than non-fraud data.
What does this entail? Basically our model will be able to detect buying reals with good precision, after all, he “studied” 1 million cases and knows what he does. On the other hand, when trying to detect real frauds, he may not do so well, that is because he only “studied” 1,000 cases of fraud, perhaps he is not so good at making this type of prediction.
In brief:
Precision and Recall

But after all, how do we detect that we really have problems with unbalanced classes?
Let’s say that you have not seen the distribution of classes previously and decided to train your model and obtained an average accuracy of 80%, it may seem that the performance was good, but no, it was not.
Anyway, who can really tell us our problem exactly? We call these heroes “Valuation Metrics” — Precision and Recall.
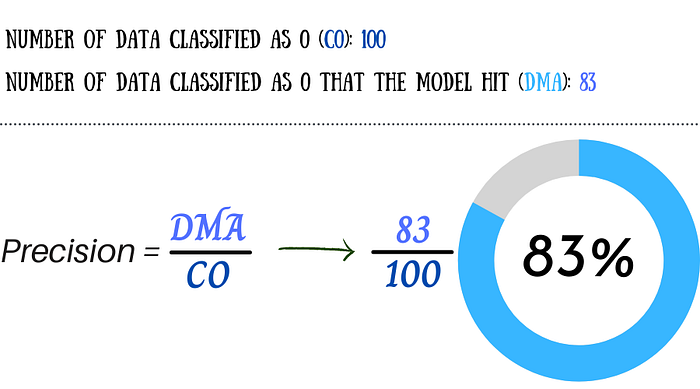
Precision: As the name implies, Precision measures the accuracy of the model. Given a total number of ratings like 0, how many of those ratings did my model predict correctly? Imagine that we have 100 dice that are classified as 0, if my model hits 83 of them, we say that we have a model with 83% accuracy.
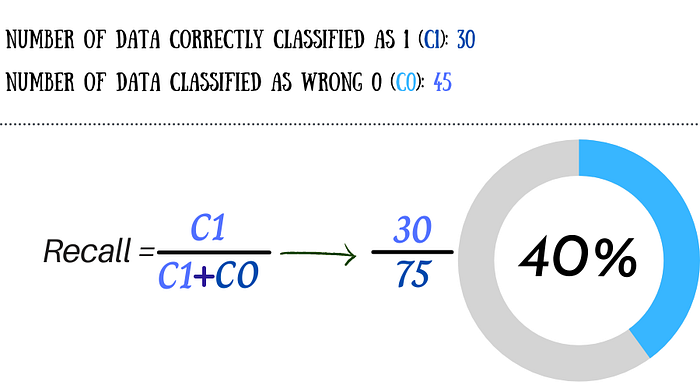
Recall: I will explain in a very detailed way as this can be a little more complex to understand. Imagine that in that same model, we have a total of 100 dice, in these 50 they are classified as 0 and the other 50 as 1. For them, our model correctly classifies 1 as a total of 30 dice and for 0 it incorrectly classifies a total of 45 Recall is basically the ratio between those correctly classified as 1 (or 0, there is also a Recall value for each classification) by adding them to the wrong classifieds of 0. In this case we have a Recall of 40% (30 divided by 45 +30).
Identifying the Problems:

I used a data set with unbalanced classes and got the following result:
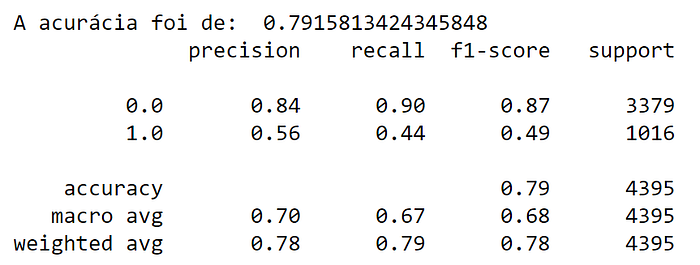
Realize that Precision and Recall for the classification as 1 are extremely low, even so we still have a good accuracy, in other words, accuracy does not always represent everything in our model. In this case, we can say that he was very good at classifying the values of 0, but not so good at classifying the values of 1.
If you want to check the Complete Notebook directly on Google Colab with further explanations click here.
Realize that even without having previously checked the distribution of the classes, with simple evaluation metrics we can check this!
But, after all, how can we get around this problem? Equate our data, and there are two main ways to do it: Oversampling and Undersampling.
Oversampling
Basically we are going to match our data through the majority class. but how so? Imagine that we have two classes, one of them has 1000 dice and the other only 100, we will increase this last one until it has 1 thousand dice too!
Here is an example:
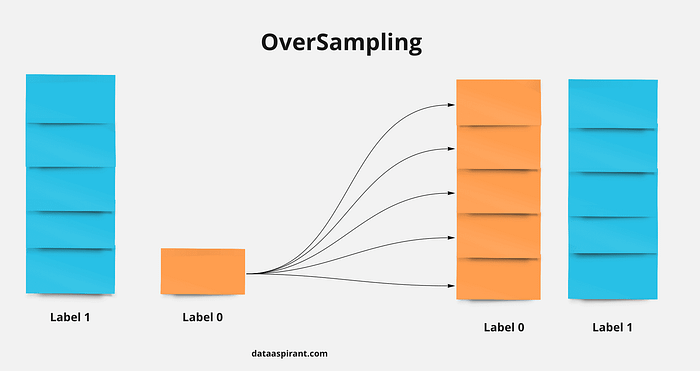
In our examples, what in the image is called a “label”, here we call a class.
Note that the number of data on “label 0” has been increased. But how?
Simple, creating synthetic data.
There are several ways to do this, and of course there is a whole logic to doing this, I will not go into details of how this article works.
The form we will use will be called SMOTE (Synthetic Minority Over-sampling Technique), this algorithm automates all functions for the user!
When we apply it to our data, we will have the following results:

Now we have not only achieved greater accuracy, but we have also improved many of the precision and recall parameters.
Application of SMOTE in code:
# importing SMOTE:
from imblearn.over_sampling import SMOTE# instantiating SMOTE:
smote = SMOTE()# applying SMOTE to our data ("training"):
X_values, y_values= smote.fit_sample(X_values, y_values)# Now just use them in your Machine Learning model
However, life is not a bed of roses, creating synthetic data can cause problems!
Let’s go to the facts, I used the word Synthetics, that is, non-real data, created by an algorithm that tries to replicate patterns that it observes in the data. Depending on the amount of data we may have a problem called Overfitting.
Overfitting: As its name suggests, “we train too much”. In this case, our model is very good at predicting training data ONLY! That is, the model cannot generalize the data well.
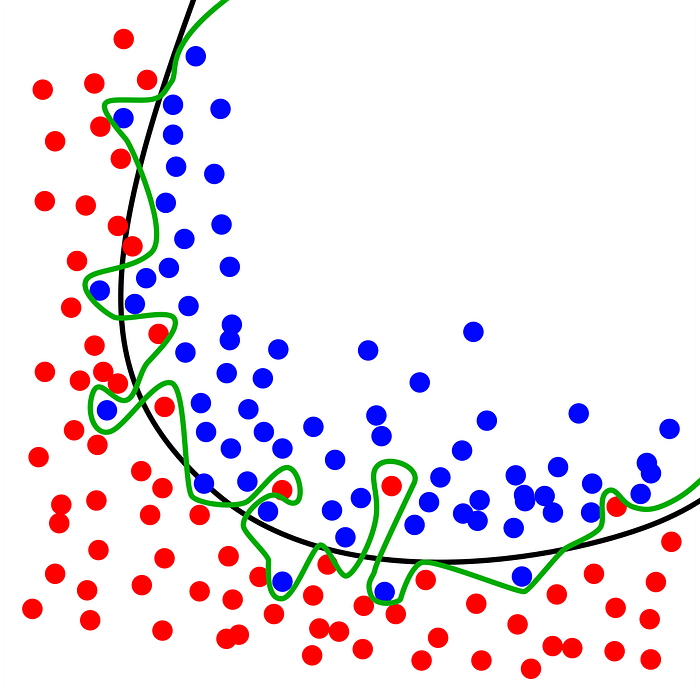
Note that in this example we have two classes marked with dots in blue and red. The black line represents a model that generalizes the data well, while the green line is an Overfiting model, instead of creating an equation that can predict any data entry, it creates an equation that mimics the training data. This can happen when we have very similar data, just what SMOTE does, it creates similar synthetic data.
Undersampling:
On the other hand we have Undersampling which basically does the same thing as Oversampling, only the other way around.
In undersampling, instead of increasing the data, we are going to decrease it, that is, we are going to take the majority class and decrease its data so that it has the same amount as those of the minority class.
In this case there is no creation, just a selection of data. See the following example:
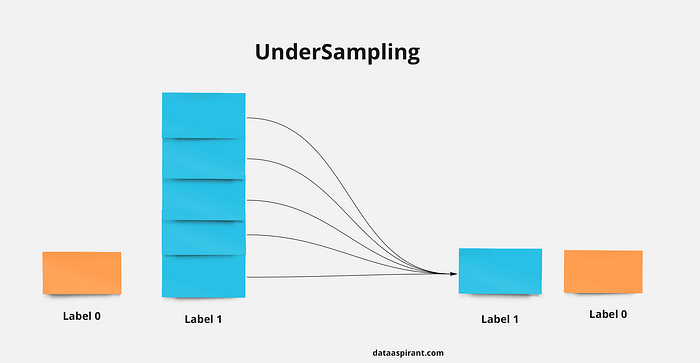
In this case, we decrease the “label 1” (or class 1) so that it has the same quantity as the label 0.
Although it is simple to do, that is, we basically select data, there is an algorithm that helps us, we call it NearMiss. When we applied them to our data set we obtained the following result:
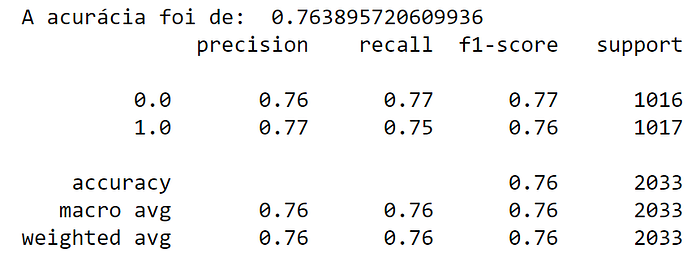
Here we had less accuracy, but the problem of precision and recall was solved.
NearMiss application in code:
# importing SMOTE:
from imblearn.under_sampling import NearMiss# instantiating SMOTE:
nm = NearMiss()# applying SMOTE to our data ("training"):
X_values, y_values= nm.fit_sample(X_values, y_values)# Now just use them in your Machine Learning model
Just as in Oversampling we have the problem of Overfitting, in Undersampling we have the problem of Underfitting.
Underfitting: Now, if this time, instead of increasing the data, we did it to reduce it, our model now “studies” less, or something like that. The less data, the less complex the equation predicts any classification.
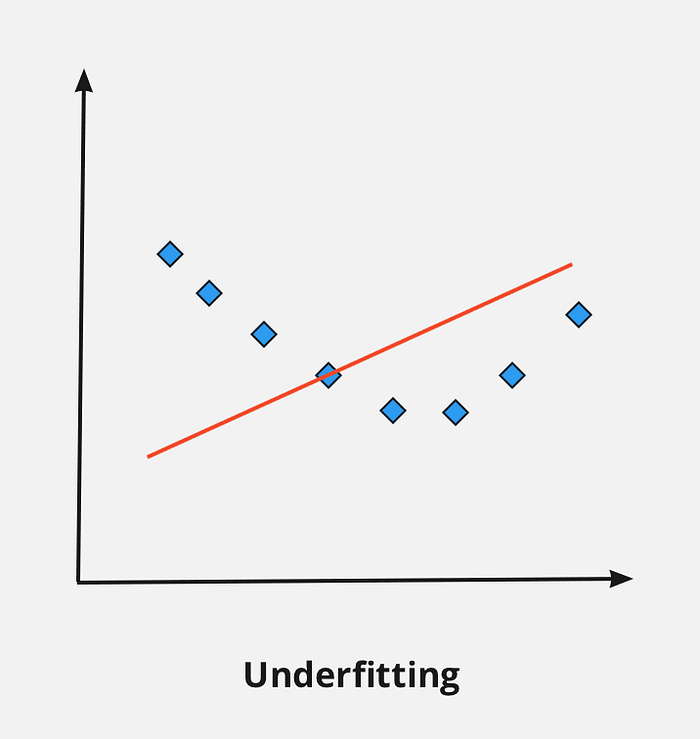
Note that in this new case we have a generic line (equation). As we have little data being used for training, we will have less information when building our Machine Learning model.
Conclusions:

Problems of unbalanced classes will be common problems in your life as a Data Scientist, either in personal projects, or in solving problems in the company where you work.
See that what I did here was to show an overview of the situation. I do not claim that SMOTE is better than NearMiss, in fact for this case SMOTE did better in the analysis, each case is a case. which one your model does better.
If you want to access all the code and deeper analysis, please consider accessing the Notebook on Google Colab of this article here.
